What is DataPelago Accelerator for Spark?
DataPelago Accelerator for Spark (DPA-S) is a pluggable accelerator built to deliver order(s)-of-magnitude price-performance advantage. This is accomplished through a completely reinvented query processing accelerator, fully optimized to leverage the advanced hardware and off-the-shelf accelerated compute instances in the cloud. DPA-S accelerates data processing workloads running on Apache Spark engines.
Why DataPelago Accelerator for Spark?
DPA-S allows you to process any type of data at unprecedented price/performance using accelerated computing hardware.
DPA-S is fully complementary to any other Spark performance enhancements you may have, such as query logic, query optimization, data schema, data layout, data caching, etc.
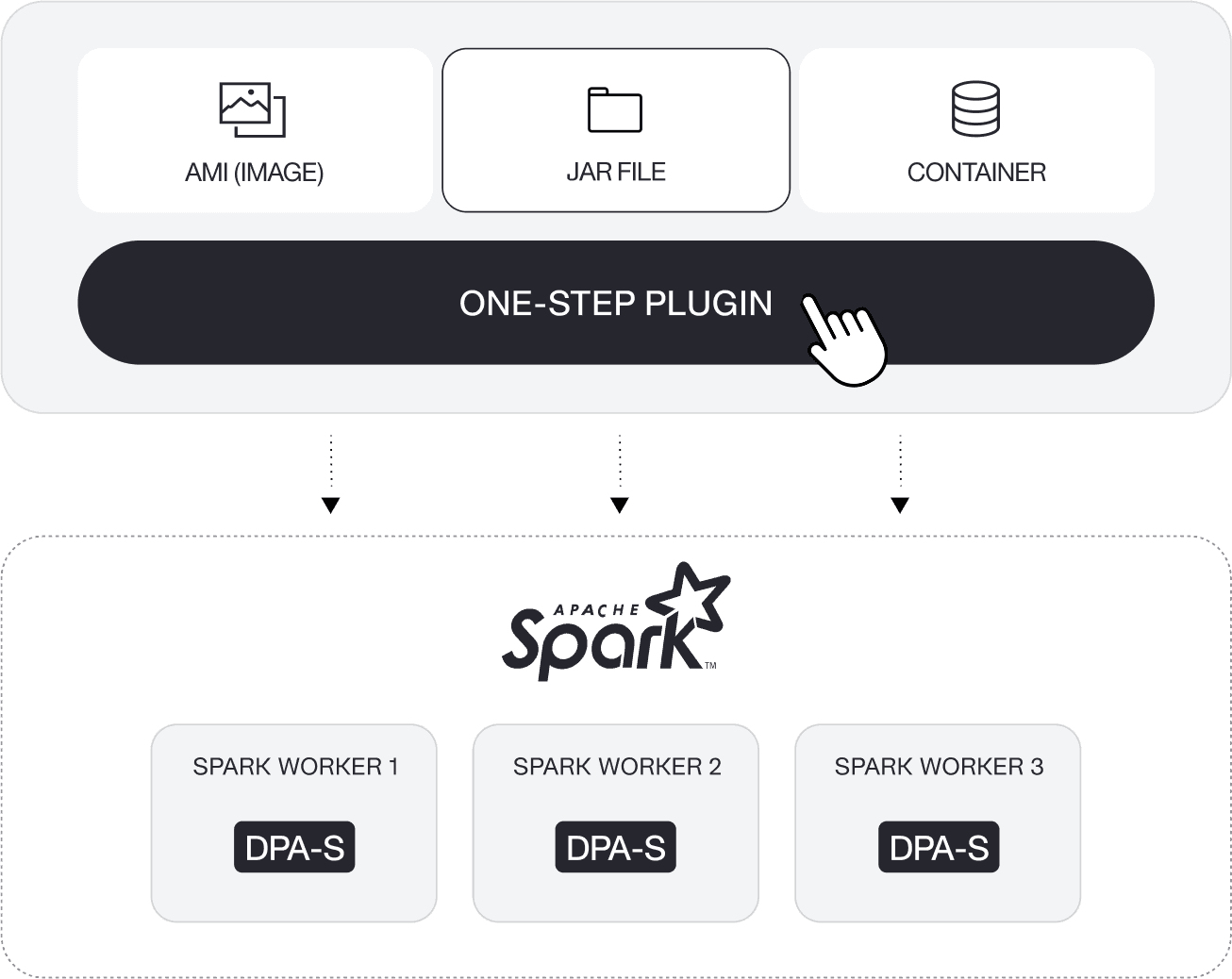
Plug-n-Play: You can quickly adopt, deploy, and operate the DPA-S plugin in one step with minimal IT effort and without any disruption to business users’ experience.
No migration required. DPA-S seamlessly integrates with your existing Spark clusters and co-exists with your current analytics tools with zero migration pains.
No change required to your application, tools, or processes. You continue to use your Apache Spark deployments and your favorite SQL and business intelligence tools to access and analyze the data.
No change required to your data or metadata. Supports open table formats, and the data formats supported by Spark. Furthermore, the data you process with DPA-S never leaves your environment and is managed in accordance with your governance process and tools.
No vendor lock-in with easy insertion and easy removal.
DataPelago offers flexible deployment models that can align with your requirements.
Use cases
DPA-S is an accelerator for Apache Spark, and supports acceleration for all the workloads of Spark that use SparkSQL, DataFrame API or SQL queries. Typical use cases include:
1. ETL/ELT (Extract, Transform, Load) Workloads
ETL/ELT is a well known data integration process where data is Extracted from various sources, Transformed into a consistent and usable format, and then Loaded into a destination system, such as a data warehouse or data lake. Following are a few examples of use cases and typical operations used in such workloads:
CSV and JSON functions are used during ingestion from raw logs or external feeds, parsing JSON logs, or flattening nested structures.
Transforming schema-on-read data formats.
Deduplicating and summarizing raw records.
Table read/scans, DML operations, pre-aggregate tables, creation of materialized views and pre-aggregated tables etc.
Standardizing, normalizing/denormalizing and reconciling data.
Data type conversions, string manipulations, date/timestamp standardizations, and conditional functions during data cleaning and transformation.
Aggregate, array, and struct functions are common in data normalization and enrichment.
2. Analytics, Business Intelligence (BI) & Reporting Workloads
BI/Reporting workloads are commonly used in decision support systems. Following are few examples of use cases and typical operations used in such workloads:
Generating daily/weekly sales and operations reports.
User behavior and segmentation analysis.
Dashboard pre-aggregation pipelines.
Frequent use of filtering, aggregations, window functions, JOINs, sorting, slicing and dicing.
Conditional, statistical and math functions are used for processing KPI and metrics, etc.
String manipulations for formatting and categorization.
3. Data Science & Feature Engineering
Data science use cases are focused on extracting knowledge from typically large data sets using various data analysis techniques.
Feature Engineering is a crucial preprocessing step in Machine Learning pipelines that involves making data more suitable for a model, often by extracting, creating, and encoding relevant information from the raw data.
Following are a few examples of use cases and typical operations used in such workloads:
Time series preparation. (e.g., rolling averages)
Sessionization and clickstream analysis.
Building ML-ready feature tables.
Ad-hoc and exploratory queries, heavy on table scans and JOINs.
Lambda, map, array, and struct functions are core to feature engineering and data reshaping.
Math and conditional functions are used for feature scaling, binning, and encoding.
Window functions for time-based or customer-based behavior metrics.
4. GenAI Data Preparation
Data preparation for generative AI involves collecting, cleaning, and transforming data to ensure high quality, relevance, and ethical standards before model training. Following lists examples of few use cases and typical operations used in such workloads:
Curating instruction-tuning datasets. This may use String, JSON, and data type conversion functions in the SQL queries.
Document processing for RAG pipelines
Tokenization and text processing
Transforming data into a suitable format for model consumption
Fix inaccuracies and remove bias.
Extract knowledge and metadata from documents, CSV, and text files.
Group and contextually align training samples using SQL operations such as aggregations and Window functions.