Deploy on AWS
Supported Versions
DataPelago Accelerator for Spark(DPA-S) is available on AWS for OSS Spark on EKS. The Docker containers with DPA-S and OSS Apache Spark are available in AWS Elastic Container Registry(ECR).
The AWS accounts you register as part of the subscription will have access to the container images.
Deployment Type |
Data platform version & Env |
OS |
Artifact Name |
|---|---|---|---|
Docker Container |
OSS, Spark 3.5.1, Java 11, Scala 2.12 |
Ubuntu22 |
600068325865.dkr.ecr.us-east-1.amazonaws.com/dpas/oss-spark-3.5.1-ubuntu22-dpas-eks:<version> |
The following sections describe how you can deploy, manage and use your EKS clusters with DPA-S.
Prerequisites
This document assumes you are familiar with deploying, managing, troubleshooting and using Apache Spark on AWS/EKS, independent of DPA-S. Various sections build on this prior knowledge of the reader, and explains how to deploy and use DPA-S.
Subscription details
When you subscribe for DPA-S, you will provide your AWS Account IDs where you wish to deploy DPA-S and you will receive the following details from DataPelago. You must provide these details when using the DPA-S container.
Subscription ID: Identifies the specific DPA-S subscription which is tied to your AWS accounts that are authorized to use the Subscription ID.
License Bucket Path: This is the S3 bucket path where DPA-S can find a valid license.
Security
The DPA-S plugin seamlessly fits into the AWS environment so that all the current security mechanisms you may have enabled as part of AWS/IAM, EKS and any other required cloud services continue to apply when using DPA-S clusters.
During the DataPelago subscription process, you must register the AWS account IDs that should be authorized to use the DPA-S plugin.
Your AWS Account and other principals who may create and run DPA-S powered Spark clusters, must have the following access privileges:
Read access to the DPA-S License Bucket Path
There are no additional security related requirements to use DPA-S. You can continue to use your current security mechanism for authentication, authorization, SSO etc.
Refer to AWS IAM documentation for more details.
Deploy on EKS Cluster
Refer to the corresponding version of Spark’s documentation for general information about running Spark with Kubernetes clusters. Following Spark and EKS documentation provides more details on deploying workloads to Kubernetes clusters:
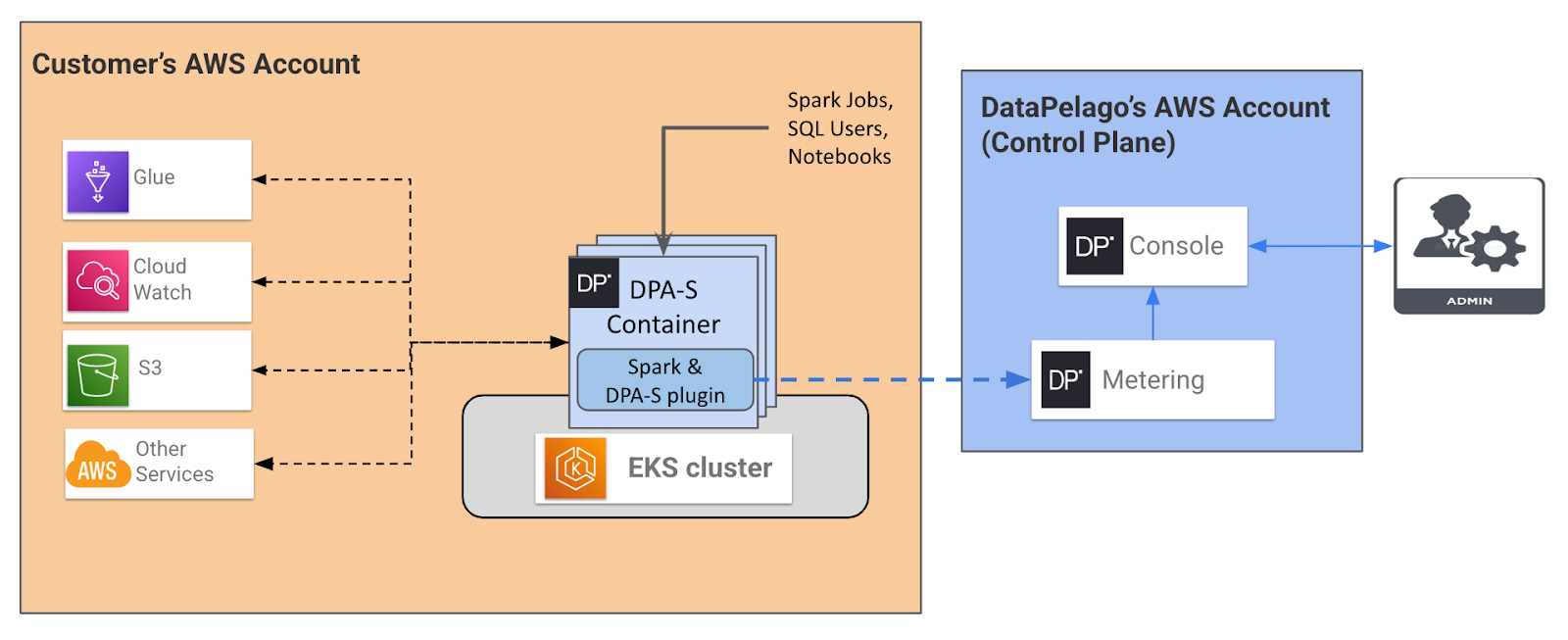
The following diagram depicts the deployment architecture for DPA-S on EKS clusters.
The DPA-S container contains the DPA-S plugin along with the supported Spark image.
Blue boxes represent DataPelago-owned and managed components for the Administration Console.
Orange box represents customer’s AWS account, and different boxes in there represent infrastructure and other services that are the responsibility of the customer.
The blue DPA-S container boxes represent DPA-S components provided by DataPelago whose operation is entirely under the control of the customer.
Blue lines indicate communication between DataPelago components.
Black lines indicate inter-component communication pre-existing in the customer environment independent of the DataPelago products and services.
The dashed lines indicate configurability to control/avoid the specific communication channel.
Note that, when using the DPA-S container DPSA_IMAGEs,
You must specify the mandatory Spark settings with appropriate values, and
You are advised to specify the recommended spark settings with the suggested values.
You should also specify any other Spark settings as needed for your application, such as:
spark.executor.instances
spark.executor.cores
spark.executor.memory
spark.driver.cores
spark.driver.memory, etc.
Mandatory Spark Paramters
Spark parameter name |
Example Values |
|---|---|
spark.plugins |
org.apache.gluten.GlutenPlugin |
spark.gluten.dp.subid |
<Your Subscription ID> |
spark.kubernetes.container.image |
<DPAS Container image path> |
spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID |
<Your Subscription ID> |
spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION |
<DPAS License bucket path> |
spark.executorEnv.DPSA_SUBSCRIPTION_ID |
<Your Subscription ID> |
spark.executorEnv.DPSA_LICENSE_LOCATION |
<DPAS License bucket path> |
spark.driver.extraJavaOptions |
-Dio.netty.tryReflectionSetAccessible=”true” NOTE: This value should be appended to existing Java options. |
spark.executor.extraJavaOptions |
-Dio.netty.tryReflectionSetAccessible=”true” NOTE: This value should be appended to existing Java options. |
spark.memory.offHeap.enabled |
“true” |
spark.memory.offHeap.size |
<appropriate positive value> |
spark.shuffle.manager |
org.apache.spark.shuffle.sort.ColumnarShuffleManager |
Recommended Spark Paramters
Spark parameter name |
Example Values |
|---|---|
spark.sql.cbo.enabled |
“true” |
spark.sql.cbo.planStats.enabled |
“true” |
spark.sql.cbo.joinReorder.enabled |
“true” |
Instructions to run your Spark Application with DPA-S Container
The following lists the steps to run a spark application using the DPA-S container image. Note that, there may be other methods to run Spark applications, and you may use the approach of your choice.
Step1: Create EKS cluster with the master node and worker node-pools
This is a generic step to create a EKS cluster, as a pre-requisite for Step2, and is independent of DPA-S as such. Refer to the EKS documentation for details about creating clusters. For example, using AWS API you can create the cluster as shown below:
#Create EKS cluster
eksctl create cluster --name ”my-eks-dpas-cluster” \
--region ${REGION} \
--version ${EKS_VERSION} \
--without-nodegroup
#Create Driver and Executor node groups. Refer to EKS and
#ekectl docs for details about the .yaml file and its contents.
eksctl create nodegroup --config-file eks-nodepool.yaml
Step2: Deploy the spark application using the DPA-S container image
Run your Spark application using any of the standard ways to run a Spark application. The following example uses the spark-submit command, and specifies the mandatory settings and the Spark executor/driver resource settings. You should use appropriate resource setting values for your environment, and may specify any other Spark settings as needed for your application. Refer to DPA-S Memory Configuration for guidance on the memory settings.
NOTE: For DPA-S 3.1.7 or earlier releases, you may see the following error message in logs. Please ignore that message:
"failed to get org id: <details>”
export DPSA_DOCKER_REPO="583557135611.dkr.ecr.us-east-1.amazonaws.com/dpas"
export DPSA_IMAGE="${DPSA_DOCKER_REPO}/oss-spark3.5.1-ubuntu22-dpas-eks:<version>"
export DPSA_SUBSCRIPTION_ID="<my subscription ID>"
export DPSA_LICENSE_LOCATION="s3://datapelago-dpas-lic/${DPSA_SUBSCRIPTION_ID}"
spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
### <DPAS mandatory parameters>
--conf spark.kubernetes.container.image=$DPSA_IMAGE \
--conf spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.executorEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.executorEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.gluten.dp.subid=$DPSA_SUBSCRIPTION_ID \
--conf spark.plugins=org.apache.gluten.GlutenPlugin \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"\
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=35g \
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \
### <DPAS recommended parameters>...
--conf spark.sql.cbo.enabled=true \
--conf spark.sql.cbo.planStats.enabled=true \
--conf spark.sql.cbo.joinReorder.enabled=true \
### <your optional spark parameters>...
--conf spark.kubernetes.memoryOverheadFactor=0.1 \
--conf spark.executor.instances=8 \
--conf spark.executor.cores=7 \
--conf spark.executor.memory=5g \
--conf spark.executor.memoryOverhead=4g \
--conf spark.driver.cores=14 \
--conf spark.driver.memory=45g \
my-application.py
Upgrading or Patching DPA-S
No additional steps are required to upgrade or patch the DPA-S container. As explained in the Deploy on EKS section, you can specify the details of the DPA-S container at the time of submitting your Spark application. So, you can run two different Spark applications with two separate versions of the DPA-S containers by specifying respective image details.
For example, following code snippets submit version1 and version2 of the same DPA-S container image for the same EKS cluster.
Submit my-application.py on the EKS cluster using version1 of the DPA-S container image.
export DPSA_DOCKER_REPO="583557135611.dkr.ecr.us-east-1.amazonaws.com/dpas"
export DPSA_IMAGE1="${DPSA_DOCKER_REPO}/oss-spark3.5.1-ubuntu22-dpas-eks:<version1>"
export DPSA_SUBSCRIPTION_ID="<my subscription ID>"
export DPSA_LICENSE_LOCATION="s3://datapelago-dpas-lic/${DPSA_SUBSCRIPTION_ID}"
spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
### <DPAS mandatory parameters>
--conf spark.kubernetes.container.image=$DPSA_IMAGE1 \
--conf spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.executorEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.executorEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.gluten.dp.subid=$DPSA_SUBSCRIPTION_ID \
--conf spark.plugins=org.apache.gluten.GlutenPlugin \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"\
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=35g \
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \
### <Other Spark parameters>...
my-application.py
Submit my-application.py on the EKS cluster using version2 of the DPA-S container image.
export DPSA_DOC
KER_REPO="583557135611.dkr.ecr.us-east-1.amazonaws.com/dpas"
export DPSA_IMAGE2="${DPSA_DOCKER_REPO}/oss-spark3.5.1-ubuntu22-dpas-eks:<version2>"
export DPSA_SUBSCRIPTION_ID="<my subscription ID>"
export DPSA_LICENSE_LOCATION="s3://datapelago-dpas-lic/${DPSA_SUBSCRIPTION_ID}"
spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
### <DPAS mandatory parameters>
--conf spark.kubernetes.container.image=$DPSA_IMAGE2 \
--conf spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.executorEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \
--conf spark.executorEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \
--conf spark.gluten.dp.subid=$DPSA_SUBSCRIPTION_ID \
--conf spark.plugins=org.apache.gluten.GlutenPlugin \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"\
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=35g \
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \
### <Other Spark parameters>...
my-application.py
Observability
DPA-S plugin is seamlessly integrated into the AWS and EKS environments, and the DPA-S logs and metrics are respectively routed to corresponding Spark logs and metrics. So, you can continue to use your current observability tools. For example,
refer to EKS observability documentation.
Troubleshooting
Following steps describe typical flow when troubleshooting any DPA-S related issues you may encounter.
First, note that your EKS Spark cluster setup running in an AWS/EKS environment has multiple components and the DPA-S plugin comes into play only during execution of queries. So, first and foremost, look for any error logs and hints from the error messages to isolate the problem to the right component that may be causing the problem.
You should use any of your standard troubleshooting practices and resources (such as Spark logs, EKS logs, community forums) for identifying the root cause, and subsequently an appropriate solution. Below we list few generic resources:
If the error messages include names such as ‘Velox’, ‘Gluten’, ‘DataPelago’, ‘DPA’, then the failure may be related to DPA-S. In such case, check if you have hit any of the error scenarios described in the following sub-sections. If so, try to resolve the issue by following the suggested solutions.
If the issue is still not resolved, then contact DataPelago Support at support@datapelago.com with following details:
Details about the problem, the environment, scenario, and steps that led to the problem.
Error messages, and any other details indicating the problem is related to DPA-S.
Sequence of steps to reproduce the problem.