Deploy on GCP
Supported Versions
DataPelago Accelerator for Spark (DPA-S) is available on GCP for use with GCP Dataproc and with OSS Spark on GKE.
GCP Dataproc Spark: DPA-S plugs-in to Dataproc using initialization action scripts
The initialization action script, .jar files, and other related software binaries of DPA-S are made available in a DataPelago bucket.
Software distribution bucket path:
gs://datapelago-dpsa-sw/<version>The service account principals you register as part of the subscription will have access to this bucket.
OSS Apache Spark: Docker containers with DPA-S and OSS Apache Spark are available in GCP Artifactory Registry.
The service account principals you register as part of the subscription will have access to the container images.
The following table lists the details of supported platforms and versions.
DPAS_SW_LOCATION=gs://datapelago-dpsa-sw/3.1.7
Deployment Type |
Data platform version & Env |
OS |
Artifact Name |
|---|---|---|---|
Init action Script |
Dataproc 2.2.49, Spark 3.5.1, Java 11, Scala 2.12 |
Debian12 |
$DPAS_SW_LOCATION/dataproc2.2.49-spark3.5.1-debian12-dpsa-cpu-init-actions.sh |
Ubuntu22 |
$DPAS_SW_LOCATION/dataproc2.2.49-spark3.5.1-ubuntu22-dpsa-cpu-init-actions.sh |
||
Dataproc 2.1.75, Spark 3.3.2, Java 11, Scala 2.12 |
Debian11 |
$DPAS_SW_LOCATION/dataproc2.1.75-spark3.3.2-debian11-dpsa-cpu-init-actions.sh |
|
Docker Container |
OSS, Spark 3.5.1, Java 11, Scala 2.12 |
Ubuntu22 |
us-docker.pkg.dev/dpsa-451623/dpsa/oss-spark3.5.1-ubuntu22-dpas-gke:3.1.7 |
OSS, Spark 3.3.4, Java 11, Scala 2.12 |
Debian11 |
us-docker.pkg.dev/dpsa-451623/dpsa/oss-spark3.3.4-debian11-dpas-gke:3.1.7 |
The following sections describe various touchpoints of DPA-S with Dataproc and other GCP services, and how you can manage and use your clusters with DPA-S integration.
Prerequisites
This document assumes you are familiar with deploying, managing, troubleshooting, and using Apache Spark, GCP Dataproc, and Spark on GKE, independent of DPA-S. Various sections build on this prior knowledge of the reader, and explain how to deploy and use DPA-S.
Subscription details
When you subscribe for DPA-S, you will receive the following details from DataPelago. You must provide these details to the cluster creation command or UI as part of configuration.
Subscription ID: Identifies the specific DPA-S subscription to which you want to associate the Dataproc cluster being created. This also ties the scope of the GCP Organization, Project, and the Service Account principals who are authorized to use the Subscription ID.
License Bucket Path: This is the Google Cloud Storage bucket path where DPA-S can find a valid license, and stores all the metering information while the Dataproc clusters with DPA-S are active.
Security
The DPA-S plugin seamlessly fits into the GCP/Dataproc environment so all the security mechanisms enabled as part of GCP and Dataproc continue to be enforced. There are no additional security-related requirements to use DPA-S. You can continue to use the GCP/Dataproc suggested security mechanism for authentication, authorization, SSO, etc.
During the DataPelago subscription process, you must register the GCP organization, the list of project IDs and corresponding service accounts and principals that should be authorized to use the DPA-S plugin.
Your GCP Project Service Account and other principals who may create and run DPA-S powered Spark clusters, must have the following access privileges:
Read access (such as Storage Object Viewer role) to the bucket with the DPA-S software distribution binaries
Read and Write access (such as Storage Object Creator and Storage Object Viewer roles) to the DPA-S License Bucket Path
Compute resources viewer access (such as Compute Viewer role) to be able to lookup and view the compute resources allocated to the DPA-S cluster.
There are no additional security related requirements to use DPA-S. You can continue to use the GCP/Dataproc suggested security mechanism for authentication, authorization, SSO etc.
Refer to GCP documentation about Principals for more details.
Deploy on Dataproc Cluster
DataPelago Accelerator for Spark (DPA-S) seamlessly integrates into your Dataproc deployment. To take advantage of the DPA-S acceleration, you need to configure your Dataproc clusters with the DPA-S plugin at the time of creating your cluster. After that, you can continue to manage and use the Dataproc clusters or troubleshoot as usual. When you run your SQL workloads on the Dataproc cluster, DPA-S will automatically and transparently accelerate the workloads.
To deploy the DPA-S plugin, you must create a new Dataproc Spark cluster and configure it with the DPA-S plugin details and use the recommended cluster properties. Refer to Dataproc documentation for details.
Note
You cannot deploy DPA-S in an already existing cluster.
Note
For DPA-S 3.1.7 or earlier releases, you may see the following error message in logs. Please ignore that message: "failed to get org id: <details>”
You can create the cluster using GCP command line or Dataproc UI. Follow the GCP/Dataproc create cluster documentation for details.
Setting Configuration Properties
You must specify the following mandatory configuration parameters when creating the Dataproc cluster with DPA-S plugin. Remember that the Dataproc and Spark parameter settings can significantly influence application performance.
Mandatory Dataproc properties
Dataproc property
Values
Metadata property: DPSA_SW_LOCATION
<DPAS Software bucket path>
Ex: “gs://datapelago-dpsa-sw/3.1.7”
Metadata property: DPSA_LICENSE_BUCKET_PATH
<DPAS License bucket path>
Ex: ”gs://datapelago-dpsa-lic/$DPSA_SUBSCRIPTION”
Initialization action script
<DPAS init script path>
Ex: “$DPAS_SW_LOCATION/dataproc2.2.49-spark3.5.1-debian12-dpsa-cpu-init-actions.sh”
Mandatory Spark properties: Specify following properties with the suggested values.
Spark property
Values
spark.gluten.dp.subid
<Your Subscription ID>
spark.plugins
org.apache.gluten.GlutenPlugin
spark.driver.extraJavaOptions
-Dio.netty.tryReflectionSetAccessible=true
spark.executor.extraJavaOptions
-Dio.netty.tryReflectionSetAccessible=true
spark.memory.offHeap.enabled
“true”
spark.memory.offHeap.size
<memory size value> See DPA-S Memory Configuration for guidance.
spark.shuffle.service.enabled
“true”
spark.shuffle.manager
org.apache.spark.shuffle.sort.ColumnarShuffleManager
Other Properties: You may specify any other Dataproc and Spark settings as needed for your application. Following config settings are recommended for optimal performance of DPA-S, and to help with troubleshooting. Specify these if appropriate for your application.
Spark property
Values
spark.gluten.ui enabled
This is “recommended” for seeing Gluten tab in SparkUI if we want the customer to self-diagnose.
“true”
dataproc.cluster.caching.enabled
“true”
Create cluster using Command line
You can create the cluster using GCP command line tools, such as gcloud.
gcloud dataproc clusters create demodpas \
## mandatory Dataproc properties
--initialization-actions <DPAS init script path> \
--metadata DPSA_SW_LOCATION=<DPAS Software bucket path> \,DPSA_LICENSE_BUCKET_PATH=<DPAS License bucket path> \
\
## Other Dataproc properties
--image-version <DPAS supported Dataproc image version> \
--project <ProjectAuthorizedInSubscription> \
--service-account <ServiceAccountAuthorizedInSubscription> \
--scopes=cloud-platform \
--properties \
## mandatory Spark properties
spark:spark.plugins=org.apache.gluten.GlutenPlugin,\
spark:spark.gluten.dp.subid=<Your Subscription ID>\
spark:spark.driver.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true,\
spark:spark.executor.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true,\
spark:spark.shuffle.service.enabled=true,\
spark:spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager,\
spark:spark.memory.offHeap.enabled=true,\
spark:spark.memory.offHeap.size=<PositiveValue>,\
\
## Other Spark properties for your application
<other spark parameters as needed>
Example: Following command creates a cluster using the specified values
Make sure to edit the environment variable names with appropriate values for your setup before executing the command.
export CLUSTER_NAME=”my-cluster”
export DATAPROC_IMAGE_VERSION=”2.2.49-ubuntu22”
export PROJECT_NAME=”my-gcp-project”
export DPSA_SUBSCRIPTION_ID=”abcdef44-e99a-45f4-934f-5aaf4446555b”
export DPSA_SW_LOCATION=”gs://datapelago-dpsa-sw/3.1.7/”
export DPSA_LICENSE_LOCATION=”gs://datapelago-dpsa-lic/$SUBSCRIPTION_ID”
gcloud dataproc clusters create $CLUSTER_NAME \
--initialization-actions "$DPSA_SW_LOCATION/dataproc2.2.49-spark3.5.1-ubuntu22-dpsa-cpu-init-actions.sh" \
--metadata
DPSA_SW_LOCATION=$DPSA_SW_LOCATION, DPSA_LICENSE_BUCKET_PATH=$DPSA_LICENSE_LOCATION \
--project $PROJECT_NAME \
--image-version $DATAPROC_IMAGE_VERSION \
--scopes=cloud-platform \
--region us-central1 \
--public-ip-address \
--master-machine-type n1-standard-16 \
--master-boot-disk-type pd-balanced \
--master-boot-disk-size 500 \
--num-master-local-ssds 1 \
--master-local-ssd-interface NVME \
--num-workers 2 \
--worker-machine-type n1-highmem-32 \
--worker-boot-disk-type pd-balanced \
--worker-boot-disk-size 500 \
--num-worker-local-ssds=4 \
--worker-local-ssd-interface NVME \
--enable-component-gateway \
--optional-components ZEPPELIN \
--no-shielded-secure-boot \
--properties \
spark:spark.plugins=org.apache.gluten.GlutenPlugin,\
spark:spark.gluten.dp.subid=$DPSA_SUBSCRIPTION_ID,\
spark:spark.driver.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true,\
spark:spark.executor.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true,\
spark:spark.shuffle.service.enabled=true,\
spark:spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager,\
spark:spark.driver.cores=16,\
spark:spark.driver.memory=55g,\
spark:spark.executor.cores=8,\
spark:spark.executor.memory=5g,\
spark:spark.executor.instances=8,\
spark:spark.executor.memoryOverhead=4g,\
spark:spark.memory.offHeap.enabled=true,\
spark:spark.memory.offHeap.size=40g,\
Create Cluster using Dataproc UI
Use Compute Engine as the infrastructure to create the cluster
During the Setup up cluster step, select the Dataproc image. Refer to the Supported Versions.
During the Configure nodes step, select any compute engine instances supported by Dataproc.
During the Customize cluster step, set the following cluster properties. The following sections list the mandatory and optional Spark configuration parameters that can be set in the GUI. These properties will be used as the default spark configuration when a customer Spark application is started. However, users can always provide Spark settings when starting their spark application.
Mandatory Dataproc parameters
Metadata properties
Provide the subscription ID and license path values to the metadata properties.
SUBSCRIPTION_IDandDPSA_LICENSE_BUCKET_PATH, in the Custom cluster metadata section of the UI.Initialization actions
Navigate to the DPA-S plugin software distribution bucket, and to the right version folder. And, then select the init-action.sh file corresponding to the specific Dataproc image version you are using for the cluster being created.
For example, you may choose the following init-action.sh file when using Dataproc2.2 Ubuntu22 image.
gs://datapelago-dpsa-sw/3.1.7/dataproc2.2.49-spark3.5.1-ubuntu22-dpsa-cpu-init-action.sh
Mandatory Spark config settings: Specify the mandatory Spark properties with appropriate values in the Cluster properties section of the UI.
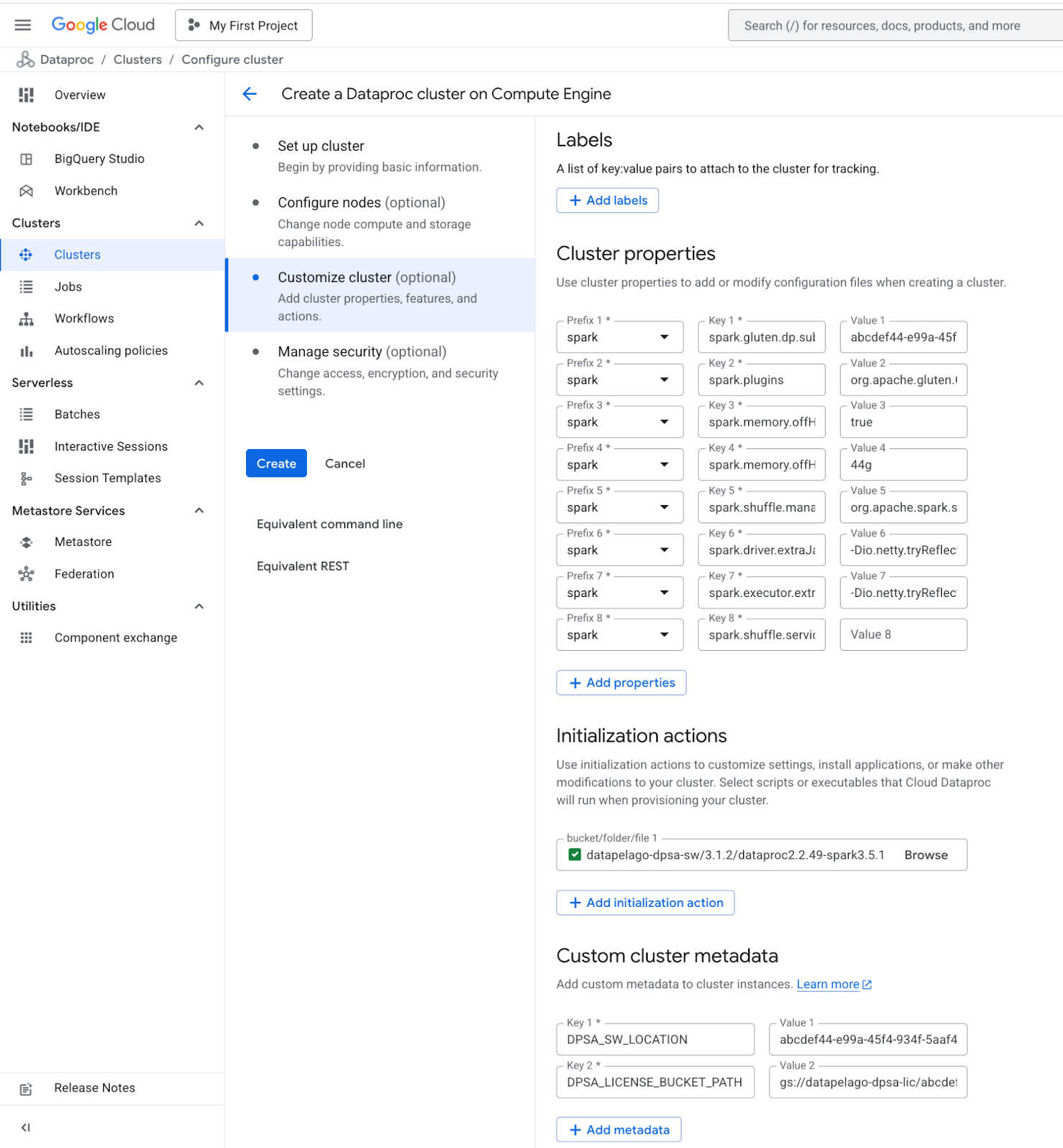
You may want to set any other Dataproc and Spark settings needed for your application in the Cluster properties section of the UI.
Deploy on GKE
DPA-S along with pre-integrated OSS Apache Spark is available as Docker container and is hosted in GCP Artifactory Registry. The service account principals you register as part of the subscription to DPA-S will have access to the container images.
Refer to section Supported Versions for details on the specific versions supported.
Refer to the corresponding version of Spark’s documentation for general information about running Spark with Kubernetes clusters. Following , Spark and GKE documentation provides more details on deploying workloads to Kubernetes clusters:
Note that, when using the DPA-S container images,
You must specify the mandatory Spark settings with appropriate values.
You are advised to specify the recommended spark settings with the suggested values.
You may also specify any other Spark settings as needed for your application, such as:
spark.executor.instances
spark.executor.cores
spark.executor.memory
spark.driver.cores
spark.driver.memory, etc.
Mandatory Spark parameters:
Spark parameter name |
Example Values |
|---|---|
spark.plugins |
org.apache.gluten.GlutenPlugin |
spark.gluten.dp.subid |
<Your Subscription ID> |
spark.kubernetes.container.image |
<DPAS Container image path> |
spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID |
<Your Subscription ID> |
spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION |
<DPAS License bucket path> |
spark.executorEnv.DPSA_SUBSCRIPTION_ID |
<Your Subscription ID> |
spark.executorEnv.DPSA_LICENSE_LOCATION |
<DPAS License bucket path> |
spark.driver.extraJavaOptions |
-Dio.netty.tryReflectionSetAccessible=”true” NOTE: This value should be appended to existing Java options. |
spark.executor.extraJavaOptions |
-Dio.netty.tryReflectionSetAccessible=”true” NOTE: This value should be appended to existing Java options. |
spark.memory.offHeap.enabled |
“true” |
spark.memory.offHeap.size |
<appropriate positive value> |
spark.shuffle.manager |
org.apache.spark.shuffle.sort.ColumnarShuffleManager |
Recommended Spark parameters
Spark parameter name |
Example Values |
|---|---|
spark.sql.cbo.enabled |
“true” |
spark.sql.cbo.planStats.enabled |
“true” |
spark.sql.cbo.joinReorder.enabled |
“true” |
Instructions to run your Spark Application with DPA-S Container
The following lists the steps to run a spark application using the DPA-S container image. Note that, there may be other methods to run Spark applications, and you may use the approach of your choice.
Step1: Create GKE cluster with the master node and worker node-pools
This is a generic step to create a GKE cluster, as a pre-requisite for Step2, and is independent of DPA-S as such. Refer to the GKE documentation for details about creating GKE clusters. For example, using gcloud API you can create the cluster as shown below:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${GCP_PROJECT} \ --zone=${GCP_ZONE} \ --scopes=cloud-platform \ --num-nodes=1 \ --machine-type=${MASTER_MACHINE_TYPE} gcloud container node-pools create workers \ --cluster=${CLUSTER_NAME} \ --project=${GCP_PROJECT} \ --zone=${GCP_ZONE} \ --scopes=cloud-platform \ --num-nodes=${NUM_WORKERS} \ --machine-type=${WORKER_MACHINE_TYPE}
Step2: Deploy the Spark application using the DPA-S container image
Run your Spark application using any of the standard ways to run a Spark application. The following example uses the
spark-submitcommand, and specifies the mandatory settings and the Spark executor/driver resource settings. You should use appropriate resource setting values for your environment, and may specify any other Spark settings as needed for your application. Refer to DPA-S Memory Configuration for guidance on the memory settings.export DPSA_DOCKER_REPO="us-docker.pkg.dev/dpsa-451623/dpsa" export DPSA_IMAGE="${DPSA_DOCKER_REPO}/oss-spark3.5.1-ubuntu22-dpas-gke:3.1.7" export DPSA_SUBSCRIPTION_ID="<my subscription ID>" export DPSA_LICENSE_LOCATION="gs://datapelago-dpsa-lic/${DPSA_SUBSCRIPTION_ID}" spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \ --deploy-mode cluster \ --conf spark.kubernetes.container.image=$DPSA_IMAGE \ --conf spark.kubernetes.driverEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \ --conf spark.kubernetes.driverEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \ --conf spark.executorEnv.DPSA_SUBSCRIPTION_ID=$DPSA_SUBSCRIPTION_ID \ --conf spark.executorEnv.DPSA_LICENSE_LOCATION=$DPSA_LICENSE_LOCATION \ --conf spark.gluten.dp.subid=$DPSA_SUBSCRIPTION_ID \ --conf spark.plugins=org.apache.gluten.GlutenPlugin \ --conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"\ --conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \ --conf spark.memory.offHeap.enabled=true \ --conf spark.memory.offHeap.size=35g \ --conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \ ### <DPAS recommended parameters>... --conf spark.sql.cbo.enabled=true \ --conf spark.sql.cbo.planStats.enabled=true \ --conf spark.sql.cbo.joinReorder.enabled=true \ ### <your optional spark parameters>... --conf spark.kubernetes.memoryOverheadFactor=0.1 \ --conf spark.executor.instances=8 \ --conf spark.executor.cores=7 \ --conf spark.executor.memory=5g \ --conf spark.executor.memoryOverhead=4g \ --conf spark.driver.cores=14 \ --conf spark.driver.memory=45g \ my-application.py
Configuration
Spark Settings
Refer to Apache Spark’s configuration page and the Dataproc cluster properties page for more details.
Using the Cluster
GKE deployments
Refer to these Instructions to run your Spark Application with DPA-S Container.
Dataproc deployments
Once a cluster is created, you start the cluster and submit your application workloads. Refer to the Managing Clusters Dataproc documentation for more details.
You can use any of the standard Web Interfaces (such as Zeppelin or Jupyter notebooks) or Spark client applications to connect to your Dataproc cluster and run application workloads. Refer to this Connect to Web Interfaces Dataproc documentation for more information.
Following screenshots show how to connect to the cluster using a notebook and submit a query.
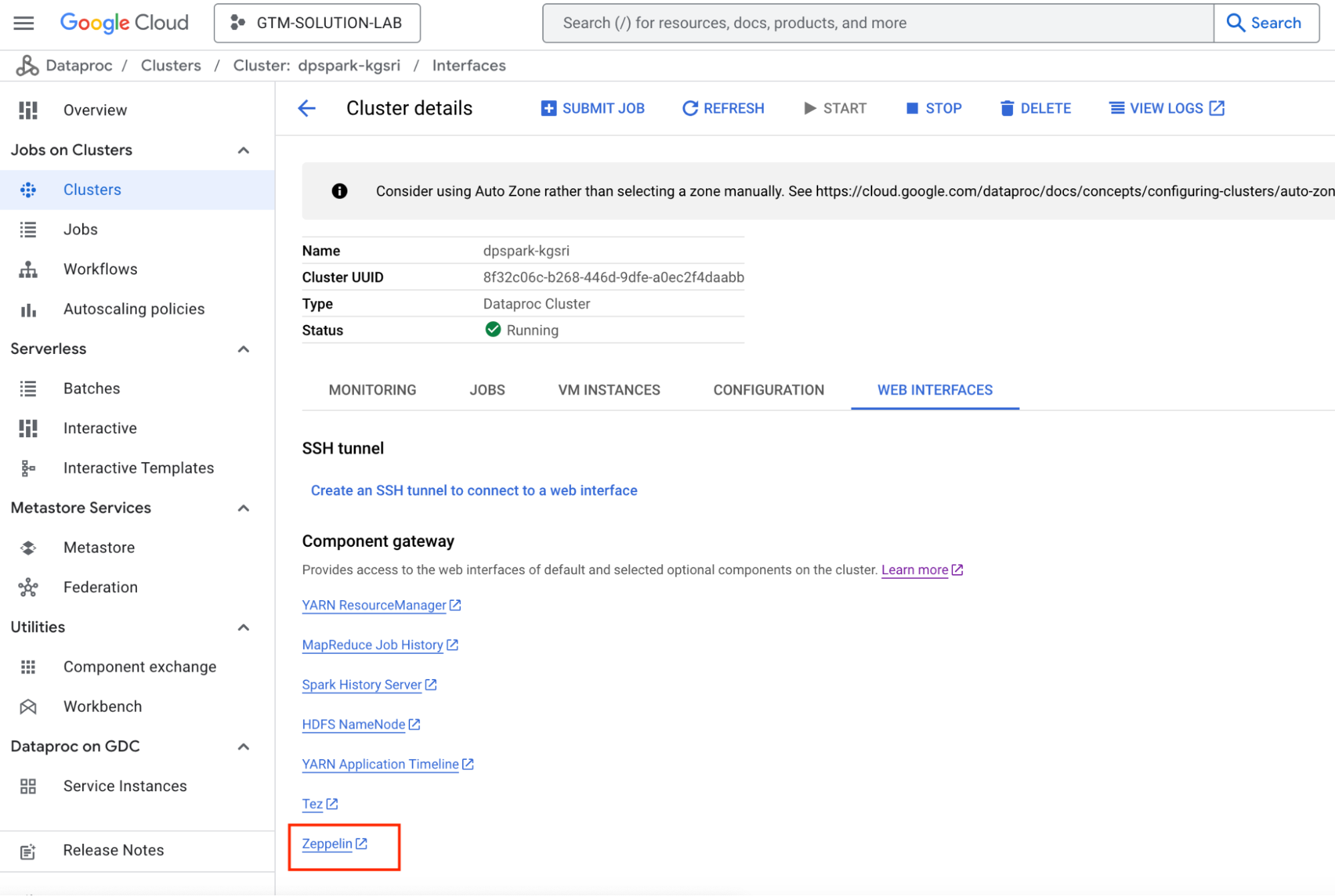
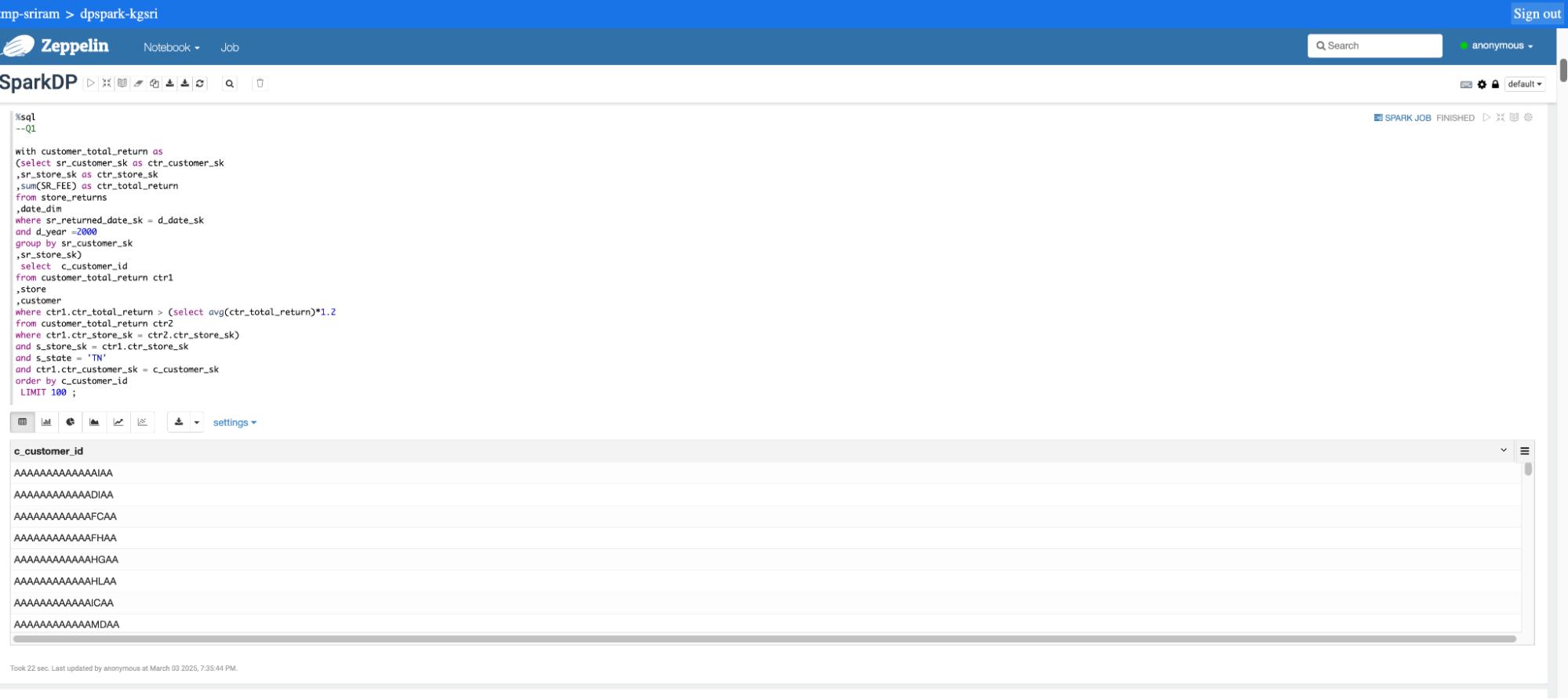
DPAS Memory Configuration
DPA-S uses Spark’s OffHeap memory mechanism. The sizing of Spark’s Off Heap memory depends on the workload.
Following steps help in finding optimal values for these Spark settings:
Initially, the total amount of memory you plan to allocate for each executor can be split in the following proportions:
spark.memory.offHeap.size= <67% of total planned executor memory>
spark.executor.memory= <23% of total planned executor memory>
spark.executor.memoryOverhead= <10% of total planned executor memory>For example, if you plan to allocate a total of 60GB to each executor, these parameters can be set as:
spark.memory.offHeap.size=40g
spark.executor.memory=14g
spark.executor.memoryOverhead=6gThe proportions can be tuned based on the execution characteristics of your workload.
Limitations
DPA-S has following limitations in the current release. Let us know at support@datapelago.com if you want us to prioritize adding any of this functionality.
ANSI Mode
DPA-S’s native CPU acceleration is not supported when ANSI mode is enabled. In this case, the queries are executed on Spark’s JVM.
Workaround: Run queries with ANSI mode disabled. You may have to modify parts of the queries to achieve same semantics.
Case-sensitive Mode
Case-sensitive mode is not supported. You may get incorrect results when spark.sql.caseSensitive = true
Workaround: Make sure your queries don’t reference any case-conflicting metadata names, such as table names, column names, partition names etc. For ex: If you have two column or partition names UserID and userid, you should rename them to be non-conflicting because of case.
Regexp Functions
DPA-S regexp functions may result in following incompatibilities:
Lookaround (lookahead/lookbehind) pattern is not supported.
When matching white space with pattern “s”, DPA-S doesn’t treat “v” (or “x0b”) as white space, unline Apache Spark does.
There may be a few other unknown incompatible scenarios.
Workaround: Enable the configuration property spark.gluten.sql.fallbackRegexpExpressions to fallback all regexp operations to Spark’s native behavior. This disables any DPA-S acceleration for the regexp operations in the query.
File Source Format
DPA-S acceleration supports Parquet file format. When other data formats are used, the scan operator may fallback to vanilla Spark’s execution, and you may not see any DPA-S acceleration. Full support for other data formats will be available in future releases of DPA-S.
Workaround: Enable DPA-S plug-in based execution initially for Parquet-based workloads and evaluate performance on other datasets before enabling them on production.
JSON Functions
DPA-S only supports double quotes surrounded strings, not single quotes, in JSON data. If single quotes are used, it may produce incorrect result.
DPA-S doesn’t support [*] in path when
get_json_object()function is called and returns null instead.
Workaround:
Change your query and data to use double quoted strings in the JSON data.
Modify [*] pattern in your query to an alternative.
NaN Support
You may get unexpected results when NaN’s are used in a query, or when the query encounters NaN’s at run time.
Workaround:
This can be worked around in different ways such as:
Modify the query if NaN’s are statically used in the query.
NaN’s may be encountered only when using floating data types, such as FLOAT or DOUBLE. Change the data type or type cast the data to DECIMAL to avoid possible generation of NaN’s.
Observability
DPA-S plugin is seamlessly integrated into the GCP/Dataproc and GKE environments, and the DPA-S logs and metrics are respectively routed to corresponding Spark logs and metrics. So, you can continue to use your current observability tools. For example,
GCP observability services GCP Cloud Logging and GCP Cloud Monitoring
For Dataproc deployments, refer to GCP/Dataproc UI for exploring logs.
For GKE deployments, refer to GKE observability documentation.
Usage and Metering Information
When you deploy DPA-S and start running Spark applications in the cluster, the DPA-S collects usage and metering information such as the amount of vCPU and memory resources used for the Spark cluster and duration the cluster is active. This information is subsequently used for billing and usage reporting purposes.
If you have purchased DPA-S through GCP or AWS Marketplace, then the usage information is reported to the respective marketplace and you will be billied accordingly by the CSP.
The metering information is saved in the License Bucket Path you specify for the property DPSA_LICENSE_BUCKET_PATH when creating the cluster. Refer to section Deploy on Dataproc Cluster for details.