Architecture
The DataPelago Accelerator for Spark (DPA-S) is a high-performance plug-in designed to optimize Apache Spark workloads by transparently leveraging heterogeneous compute resources such as CPUs and GPUs.
Built on open standards like Substrait and deeply integrated with Spark, it intercepts query execution plans and offloads eligible operators—including filters, projections, joins, aggregations, and sorts—to accelerated backends without requiring code rewrites, data migration, or changes to security policies.
Its design preserves Spark’s semantics and APIs, ensuring compatibility with existing data formats, catalogs, and connectors, while also extending acceleration to key storage and data source integrations. This seamless, transparent architecture makes the DataPelago Accelerator an enterprise-ready solution for organizations scaling data-intensive workloads.
The Accelerator seamlessly integrates with Spark as a plug-in jar, making it fully plug-and-play across Spark environments in hyperscalers, neoclouds, and on-prem deployments.
DPA-S is powered by DataPelago’s Nucleus architecture. Nucleus is designed as a Universal Data Processing Engine and the easiest pluggable technology for your lakehouse deployments running any data processing engine (such as Spark, Trino) on any hardware.
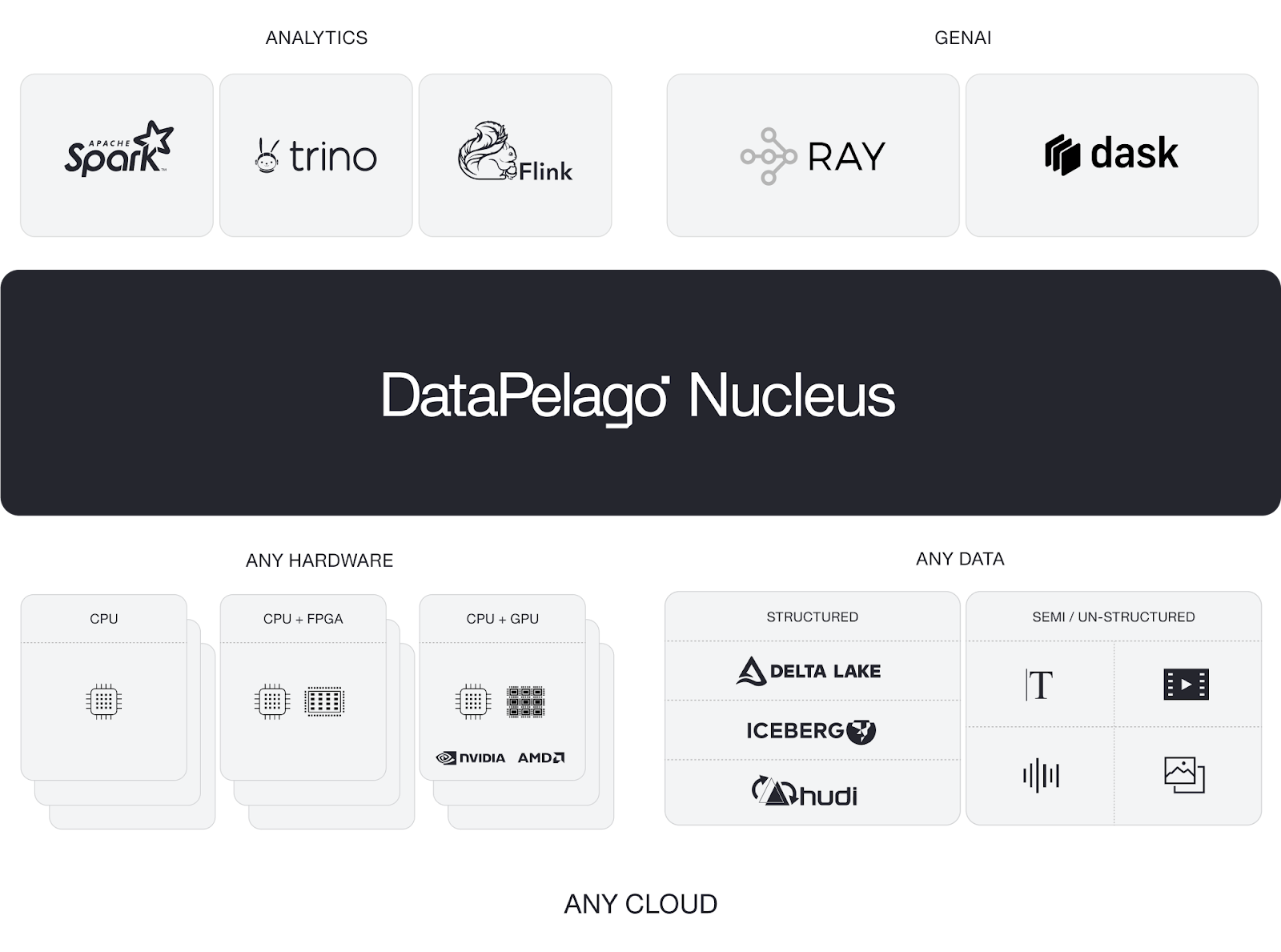
The Nucleus engine itself has three architectural components, as described below. This composable and modular architecture delivers acceleration for GenAI/LLM and Lakehouse analytics workloads developed in SQL, Python, and other widely used programming languages, permitting friction-free adoption.
Unified Query Engine with DataApp™: Seamlessly converts any query or execution plan into standards-based formats like Substrait using mechanisms like Apache Gluten. This is purpose-built for GenAI, LLMs, Lakehouse analytics. Supports native SQL, Python, and more for lightning-fast integration.
Intelligent Execution Optimizer: Dynamically orchestrates GenAI and analytics transformations by automatically building optimal execution pipelines and selecting the best-performing hardware based on real-time cost-performance analysis.
Revolutionary DataVM®: The industry’s first VM with domain-specific instruction set architecture that unleashes multi-modal data processing across any hardware—CPUs, GPUs, and beyond—leveraging proven frameworks like LLVM, CUDA, and ROCm for maximum compatibility.
Nucleus transforms the physical plan from the data processing engine’s query optimizer to use accelerated implementations of various data processing operators such as Filter, Join, Sort, etc. Then, it transparently executes these operators optimally using a combination of advanced CPU and GPU primitives depending on the available hardware. Nucleus manages the concurrent execution of these operators and maximizes efficient resource usage to dramatically reduce processing time and increase processing throughput.
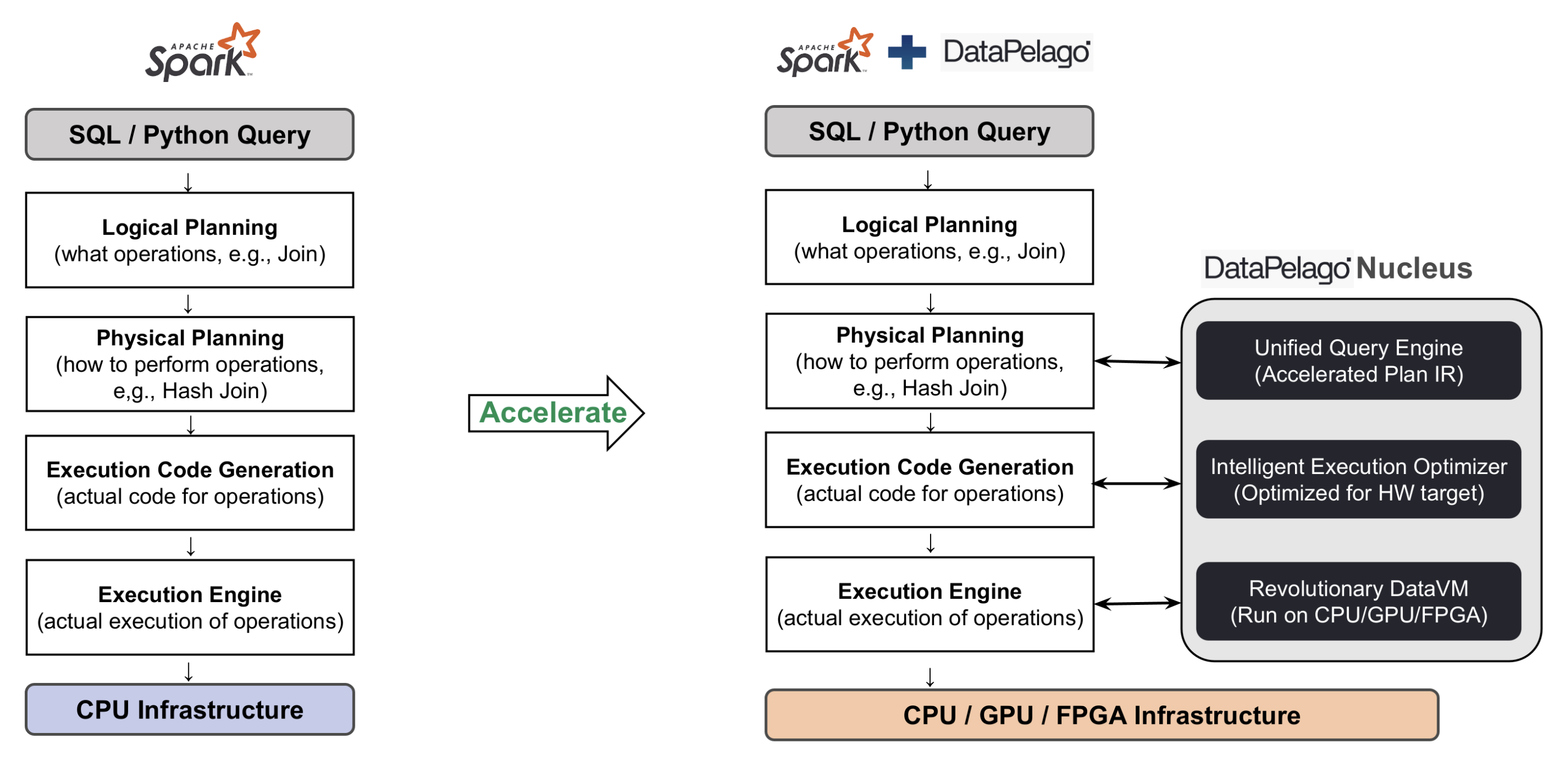
DPA-S is packaged as plug-in software that can be seamlessly integrated with the Apache Spark engine, in all Spark deployment environments including physical servers, cloud servers, virtual machines, and containers. DPA-S integrates Nucleus capabilities into the Spark driver and Spark worker nodes and does not require any changes to your infrastructure. Spark applications can continue to run on the same cluster and nodes that they originally ran on, and transparently achieve the performance and cost savings.